Soumya Shamarao JahagirdarI am a PhD student at University of Tübingen, advised by Prof. Hilde Kuhene. I am working on multimodal learning especially efficient vision-language models and video understanding. I completed my Master's by Research from IIIT Hyderabad, India under the guidance of Prof. C V Jawahar and Prof. Dimosthenis Karatzas. Previously in my undergraduate research, I have worked with Prof. Shankar Gangisetty from KLE Technological University and Prof. Anand Mishra from IIIT Hyderabad. |

|
ResearchMy research interests lie in building better multimodal models! |
NewsMay 2026: We are organizing a challenge on Time-Logic at Second Workshop on Video-Language Models for Long Videos in CVPR 2026! April 2026: MaskLLaVA and TTA-Vid are now on arxiv! March 2026: Visualoverload got accept at CVPR! September 2024: Started my PhD in University of Tübingen! August 2024: Our competition ICDAR 2024 Competition on Reading Documents Through Aria Glasses was presented by Dr. Ajoy Mondal at ICDAR in Athens, Greece! June 2024: Our paper "Prompt2LVideos: Exploring Prompts for Understanding Long-Form Multimodal Videos" got accepted at International Conference on Computer Vision & Image Processing - CVIP! April 2024: Organizing a competition on Reading documents through ARIA glasses with Meta Reality Labs! March 2024: Successfully defended MS thesis titled: Text-based Video Question Answering! February 2024: Participated in Google Research Week in Bangalore! September 2023: Attended International Space Conference in collaboration with ISRO, InSpace, and NSIL! August 2023: Our paper "Understanding Video Scenes through Text: Insights from Text-based Video Question Answering" got accepted at ICCV Workshops, VLAR! March 2023: Organized competition on Video Question Answering on News videos in ICDAR 2023. February 2023: Two papers got accepted in CVPR-2023 O-DRUM Workshop. December 2022: Student volunteer member at ICFHR conference 2023. October 2022: Our paper "Watching the News: Towards VideoQA Models that can Read" got accepted at WACV, 2023. September 2022: I started my internship at Computer Vision Center (CVC), UAB, Barcelona, Spain. July 2022: Conducted a tutorial on transformers in Summer School of AI, CVIT. May 2022: First Patent on Single Image Depth Estimation with SRIB-Bangalore got accpeted. |
Publications |

|
TTA-Vid: Generalized Test-Time Adaptation for Video ReasoningSoumya Shamarao Jahagirdar*, Edson Araujo*, Anna Kukleva, M Jehanzeb Mirza, Saurabhchand Bhati, Samuel Thomas, Brian Kingsbury, Rogerio Feris, James R Glass, Hilde Kuehne arxiv, 2026 paper This paper introduces TTA-Vid, a test-time reinforcement learning framework for video-language reasoning that adapts pretrained models to new video samples during inference without retraining. |

|
When LLaVA Meets Objects: Token Composition for Vision-Language-ModelsSoumya Shamarao Jahagirdar, Walid Bousselham, Anna Kukleva, Hilde Kuehne arxiv, 2026 paper This paper presents Mask-LLaVA, a token-efficient framework for autoregressive vision-language models that combines mask-based object representations with global and local visual features. |

|
Visualoverload: Probing visual understanding of vlms in really dense scenesPaul Gavrikov, Wei Lin, M. Jehanzeb Mirza, Soumya Jahagirdar, Muhammad Huzaifa, Sivan Doveh, Serena Yeung-Levy, James Glass, Hilde Kuehne arxiv, 2026 paper / website / dataset / Evaluation Server This paper introduces VisualOverload, a VQA benchmark designed to evaluate fine-grained visual understanding in densely populated scenes. |

|
Prompt2LVideos: Exploring Prompts for Understanding Long-Form Multimodal VideosSoumya Shamarao Jahagirdar, Jayasree Saha, C. V. Jawahar International Conference on Computer Vision & Image Processing (CVIP) Workshops, VLAR, 2024 paper / code This paper introduces a multimodal dataset of long-form lecture and news videos aimed at advancing video understanding in domains where manual annotation is costly and requires subject expertise. |

|
Understanding Video Scenes through Text: Insights from Text-based Video Question AnsweringSoumya Shamarao Jahagirdar, Minesh Mathew, Dimosthenis Karatzas, C. V. Jawahar International Conference on Computer Vision (ICCV) Workshops, VLAR, 2023 paper This paper analyzes two video question answering datasets, NewsVideoQA and M4-ViteVQA, which focus on understanding textual content within videos. |
|
Weakly Supervised Visual Question Answer GenerationCharani Alampalle, Shamanthak Hegde, Soumya Shamarao Jahagirdar, Shankar Gangisetty Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, ODRUM, 2023 paper We propose a weakly-supervised visual question answer generation method that generates a relevant question-answer pairs for a given input image and associated caption. |

|
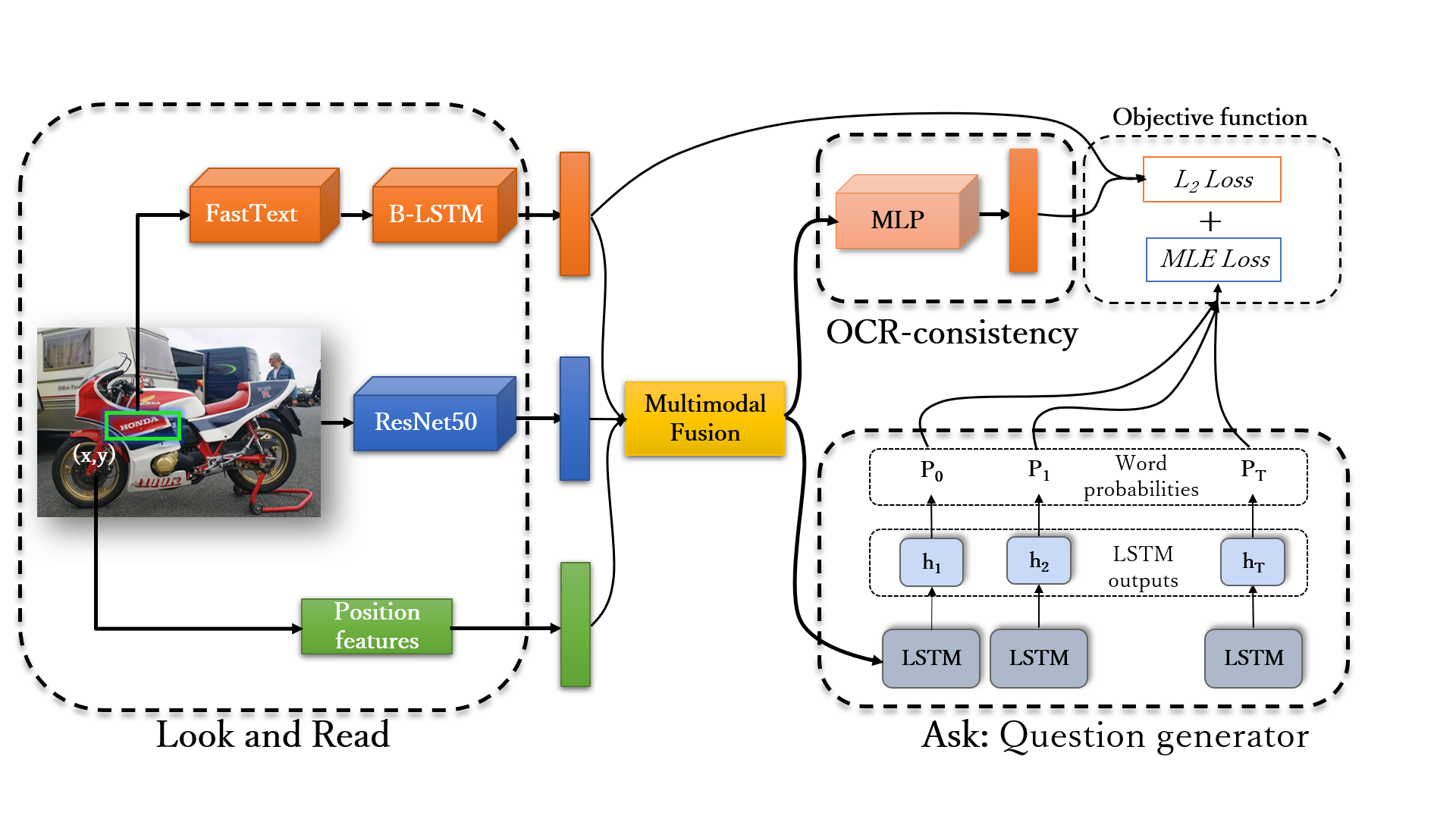
Making the V in Text-VQA MatterShamanthak Hegde, Soumya Shamarao Jahagirdar, Shankar Gangisetty Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, ODRUM, 2023 paper We propose a method to learn visual features (making V matter in TextVQA) along with the OCR features and question features using VQA dataset as external knowledge for Text-based VQA. |
|
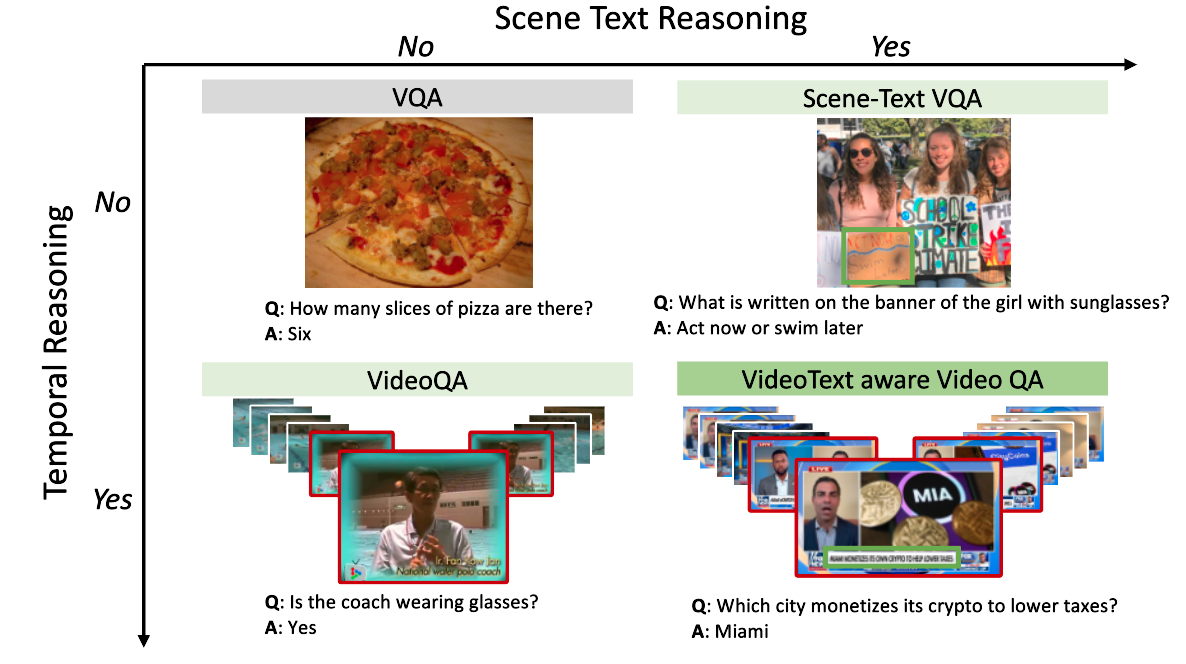
Watching the News: Towards VideoQA Models that can ReadSoumya Shamarao Jahagirdar, Minesh Mathew, Dimosthenis Karatzas, C. V. Jawahar Winter Conference on Applications of Computer Vision, WACV , 2023 paper / code / website / youtube We propose a novel VideoQA task that requires reading and understanding the text in the video. We focus on news videos and require QA systems to comprehend and answer questions about the scene and text. |
|
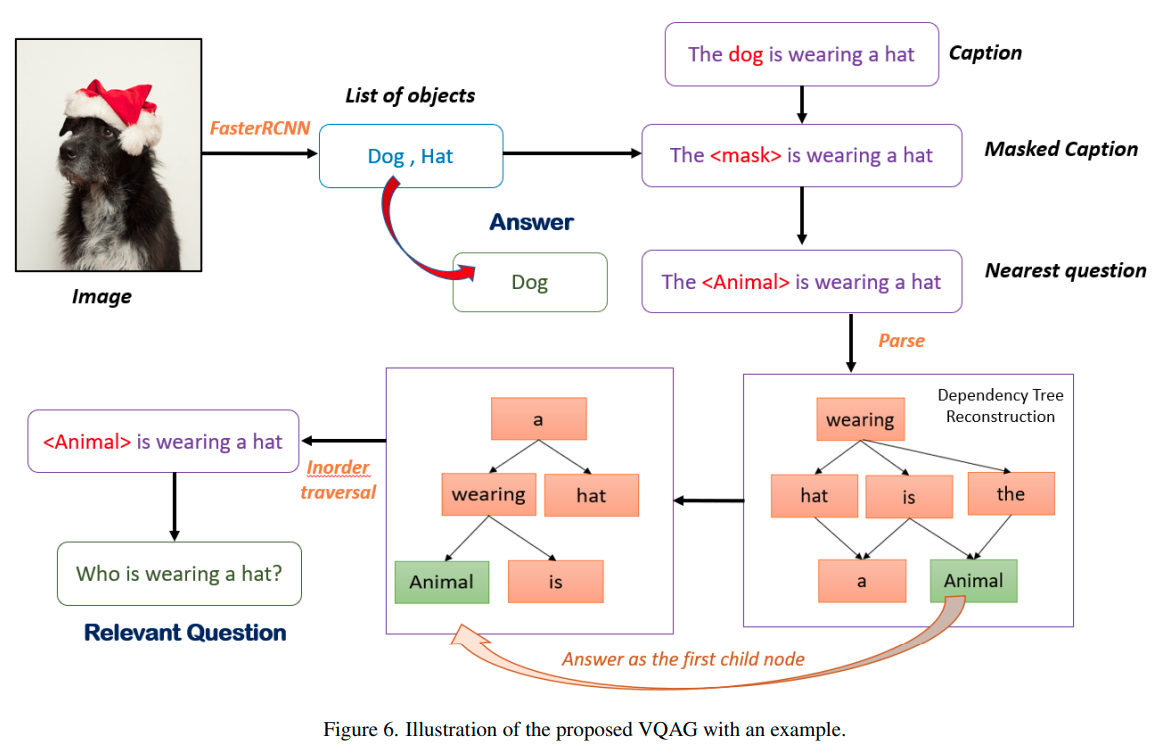
Look, Read and Ask: Learning to Ask Questions by Reading Text in ImagesSoumya Shamarao Jahagirdar, Shankar Gangisetty, Anand Mishra International Conference on Document Analysis and Recognition, (ICDAR) , 2021 paper / code / website / youtube We present a novel problem of text-based visual question generation or TextVQG in short. Given the recent growing interest of the document image analysis community in combining text understanding with visual reasoning, this task studies question generation from images containing text. |

|
DeepDNet: Deep Dense Network for Depth Completion TaskGirish Hegde, Tushar "Soumya Shamarao Jahagirdar, Vaishakh Nargund, Ramesh Ashok Tabib, Uma Mudenagudi, Basavaraja Vandrotti, Ankit Dhiman" Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, WiCV, 2021 paper We propose a Deep Dense Network for Depth Completion Task (DeepDNet) towards generating dense depth map using sparse depth and captured view. We propose Dense-Residual-Skip (DRS) Autoencoder to estimate scene depth. |
Patents |

|
Method and Device of Depth Densification using RGB Image and Sparse Depthpatent 2022-05-05 website PATENT NUMBER: WO2022103171A1; PATENT OFFICE: US; PUBLICATION DATE: 2022/05/19; Inventors Suhas MUDENAGUDI Uma, HEGDE Girish, Dattatray, Tabib Ramesh Ashok, JAHAGIRDAR Soumya, Shamarao, PHARALE Tushar, Irappa, Vandrotti Basavaraja, Shanthappa, Dhiman Ankit, NARGUND Vaishakh |
|
Design and source code from Jon Barron's website |